is.na(ChlData$Chl) [1] FALSE FALSE FALSE FALSE TRUE FALSE FALSE TRUE TRUE FALSE FALSE FALSE
[13] FALSE FALSE FALSE FALSE FALSE FALSE FALSEMissing values are important and interesting, and they can affect how functions can be used on your data.
Note that R uses NA (i.e. ‘not available’) to indicate missing values of any class (numeric, character, factor):
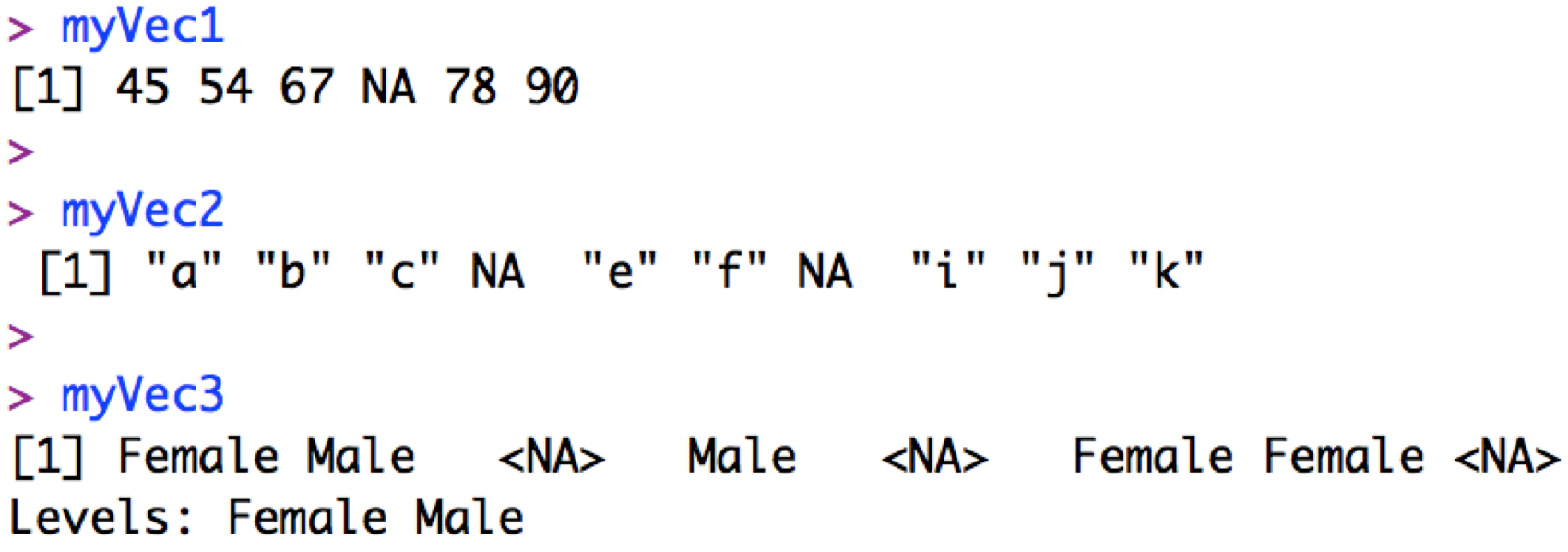
R will also use NaN (i.e. “Not a Number”) for missing numerics, and NULL when results of a function are undefined. We can also tell R what we want to consider a missing number (e.g. in some databases 9999 is used to represent a missing value) with the na.strings=... argument when we read in the data.
You can also find missing values in a vector (e.g. column) using the is.na() function:
is.na(ChlData$Chl) [1] FALSE FALSE FALSE FALSE TRUE FALSE FALSE TRUE TRUE FALSE FALSE FALSE
[13] FALSE FALSE FALSE FALSE FALSE FALSE FALSEand identify locations of missing values with:
which(is.na(ChlData$Chl) == TRUE)[1] 5 8 9You can count how many missing values you have with the length() function:
myNA <- which(is.na(ChlData$Chl) == TRUE) # locate the missing values
length(myNA) # count the missing values[1] 3You can apply functions to objects or their components when missing values are present by letting R know what you want R to do with the missing values. For example, getting the overall mean of the chlorophyll column without telling R how to handle missing values:
mean(ChlData$Chl)[1] NAvs. telling R to remove them with the na.rm = ... argument:
mean(ChlData$Chl, na.rm = TRUE)[1] 32.42375Note that the data frame itself remains unchanged (the missing values are still there), but R ignores the NAs when calculating the mean. You can find out more about how a particular function handles missing values by looking at the function’s help file (e.g. ?mean).
You can remove rows containing a missing value in a particular column with the subset() function. For example, you can remove any row with missing Month data with:
head(ChlData) # Original data frame Station Year Month Chl
1 HL2 2007 2 16.07
2 S27 2005 10 31.31
3 HL2 2002 NA 40.38
4 HL2 2001 2 32.00
5 HL2 2001 10 NA
6 S27 2007 10 29.71subset(ChlData, is.na(Month) == FALSE) Station Year Month Chl
1 HL2 2007 2 16.07
2 S27 2005 10 31.31
4 HL2 2001 2 32.00
5 HL2 2001 10 NA
6 S27 2007 10 29.71
7 S27 2006 7 59.20
8 HL2 2007 4 NA
9 S27 2004 4 NA
10 HL2 2003 5 26.00
11 HL2 1999 9 37.00
12 S27 2000 2 38.88
13 S27 2002 1 21.35
14 HL2 2004 5 28.95
15 S27 2006 6 17.77
16 S27 2003 3 55.35
17 S27 2004 1 16.69
18 HL2 2007 7 23.26
19 HL2 2005 9 44.86Note that you use is.na(Month) == FALSE here as you want to keep all rows where Month is not NA.
Also, note that there are rows with NA remaining in the Chl column.
Finally, you can remove all rows that are incomplete (i.e. containing any missing values) with the na.omit() function:
head(ChlData) # Original data frame Station Year Month Chl
1 HL2 2007 2 16.07
2 S27 2005 10 31.31
3 HL2 2002 NA 40.38
4 HL2 2001 2 32.00
5 HL2 2001 10 NA
6 S27 2007 10 29.71ChlData <- na.omit(ChlData) # Remove the NAs
head(ChlData) # Data frame without NAs Station Year Month Chl
1 HL2 2007 2 16.07
2 S27 2005 10 31.31
4 HL2 2001 2 32.00
6 S27 2007 10 29.71
7 S27 2006 7 59.20
10 HL2 2003 5 26.00Note that the above code reassigns the output of the na.omit() function back to the name ChlData. This replaces the original data frame with the new data frame without missing values. Instead, you could save it as a new object (with a new name) so the original is not overwritten.
Take a look at the numbers that print out to the left of the data frame:
head(ChlData) Station Year Month Chl
1 HL2 2007 2 16.07
2 S27 2005 10 31.31
4 HL2 2001 2 32.00
6 S27 2007 10 29.71
7 S27 2006 7 59.20
10 HL2 2003 5 26.00These are row names that were assigned when the data were read in. You can ignore row names but I wanted to to explain them as they can be distracting when one starts manipulating data frames. Unless you specify otherwise, rows are named by their original position when the data are read in to R, e.g. initially row #3 was assigned the name “3”, and row #4 was assigned the name “4”, etc. Since you have removed some rows with na.omit() above, the row names now skip from e.g. 2 to 4 (row 3 has been removed), but note that the 3rd row in the data frame can still be accessed with:
ChlData[3,] Station Year Month Chl
4 HL2 2001 2 32You can choose your own row names with the rownames() function (or column names with the colnames() function) as well as with arguments in e.g. read.csv().