Use the results of the code above to report your hypothesis testing results. Include:
a description of the terms (predictor fixed effects and any interactions) that are in your best-specified model
a comparison of these terms to the terms in your starting model - are all terms in your starting model in your best-specified model?
how much deviance in your response is explained by your model
how important each term (predictor or interaction) is in explaining the deviance in your response
descriptions of your modelled effects:
a visual representation of your modelled effects (a plot): Remember to include your model predictions, uncertainty as well as your observations. Include units on your axes and a figure number and legend.
examples of your modelled response using different values of your predictors
quantifications of your modelled effects
for each categorical predictor:
for each numeric predictor:
- the effect on your response of a unit change in your numeric predictor on the RESPONSE scale
if there is an interaction between a numeric and categorical predictor
if the numeric predictor effect is different than 0 for all levels of your categorical predictor, and
if the numeric predictor effect is the same for all levels of your categorical predictor (see example)
linking the modelled effects back to the mechanisms
consider what might be explaining the remaining (unexplained) deviation in your response
My best-specified model tells me that the growth varies with latitude and sex, and that the effect of latitude on growth varies with sex. The terms in my best-specified model are the same as those in my starting model indicating that there is evidence that the main effects of latitude and sex as well as the interaction are explaining variability in moose growth.
Together the effects of latitude and sex explain 93% of the deviance in growth rate (Likelihood ratio R2)..
Based on the sum of Akaike weights, latitude and sex are equally important in explaining the deviance in growth rate as they appear in all models with Akaike weights > 0. The interaction between latitude and sex is slightly less important appearing only in the best-specified model with an Akaike weight of 0.76.
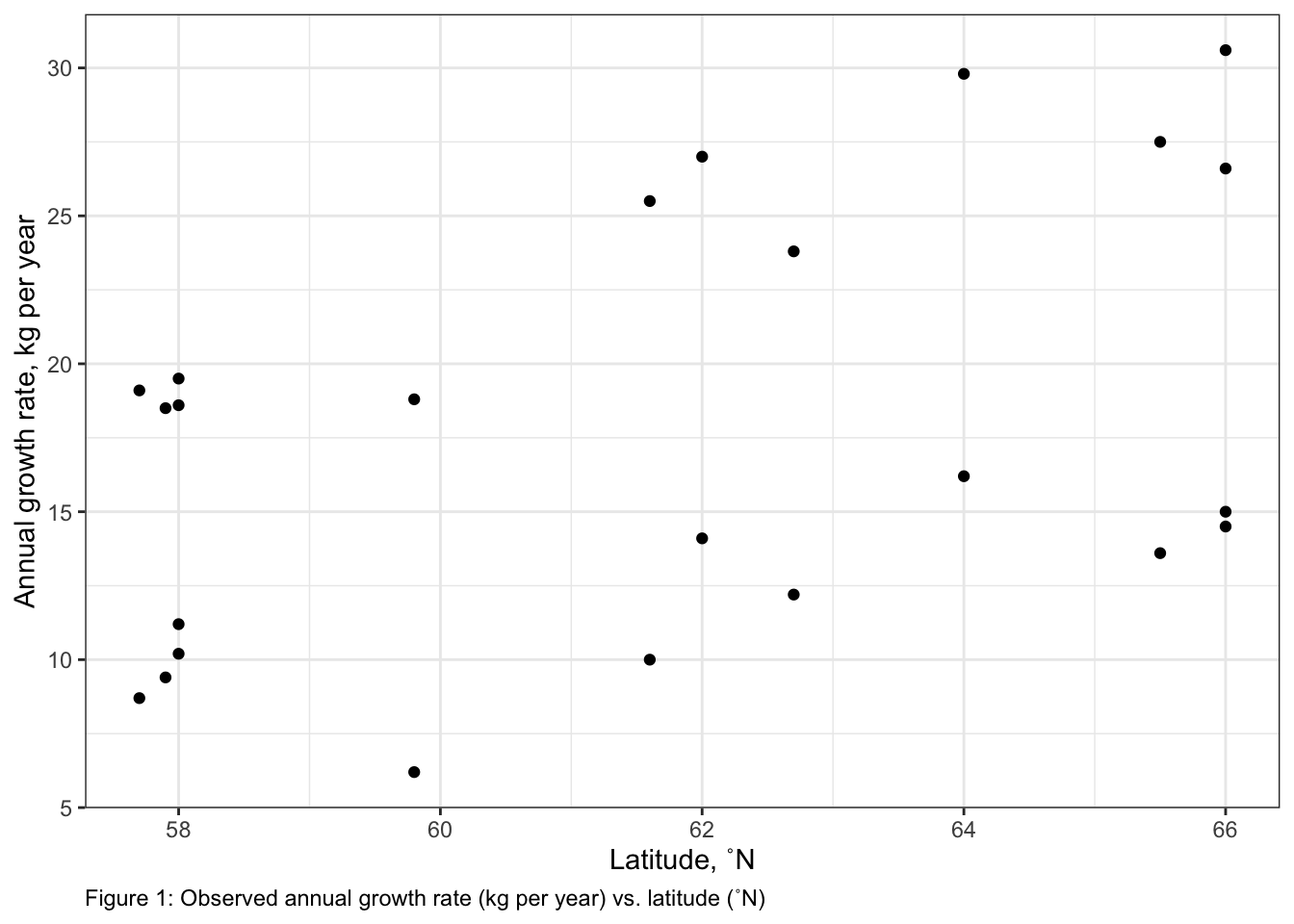
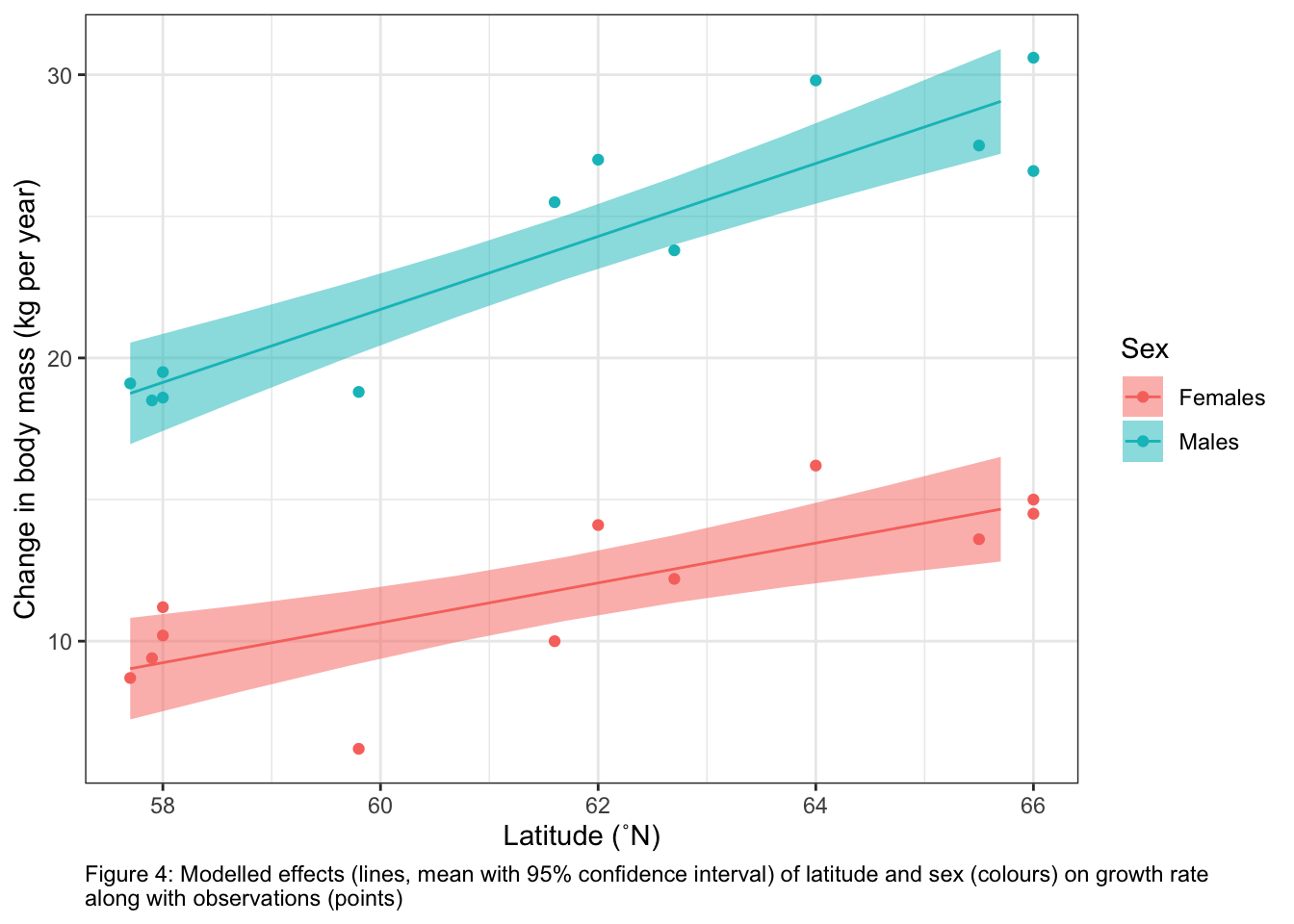
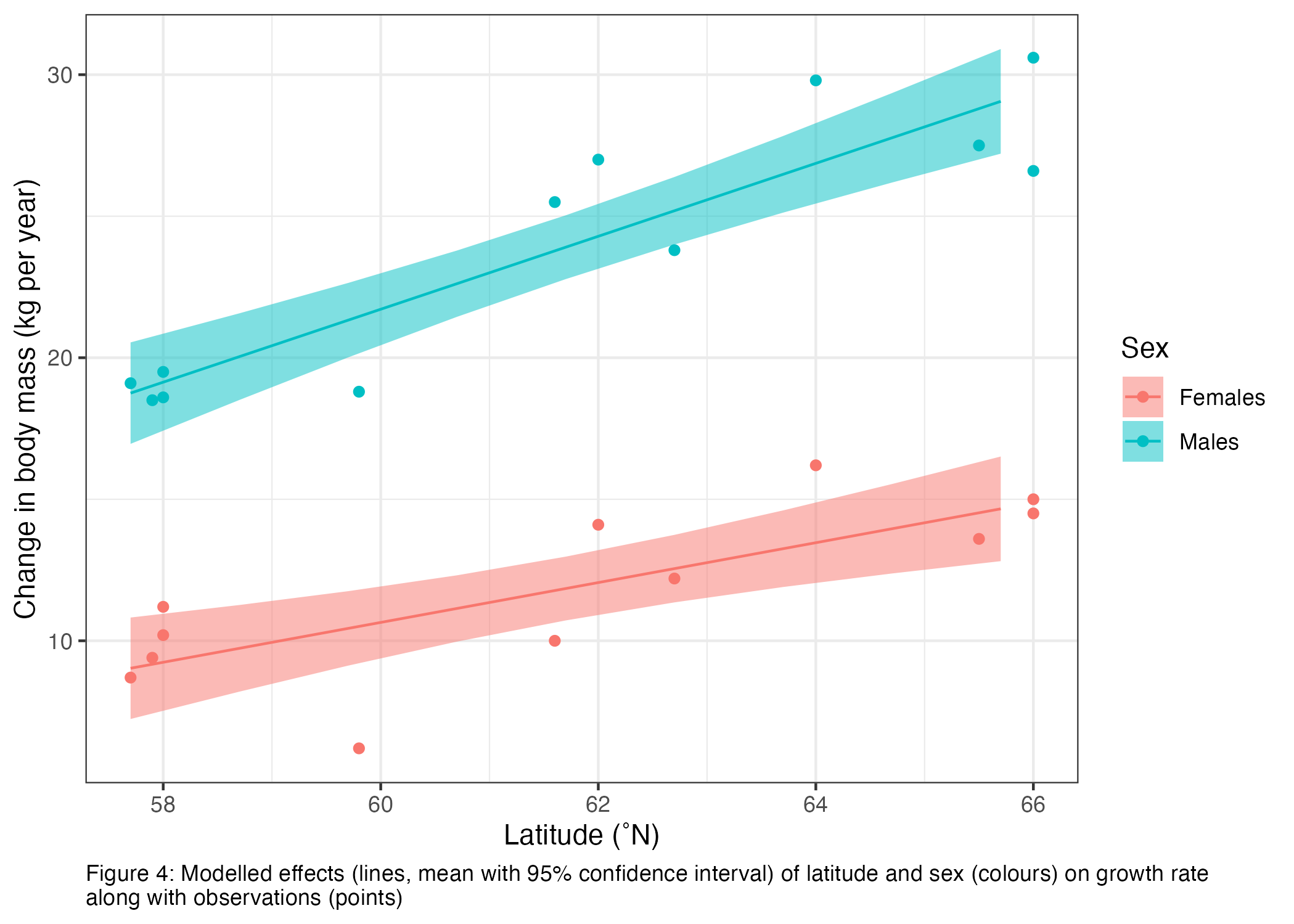
Growth rate is higher for males than females: the predicted growth when latitude is 61.6˚N (the mean of the latitudinal range) is 11.8 ± 0.6 kg year-1 for females and 23.8 ± 0.6 kg year-1 for males.. There is evidence the predictions of growth between sexes are different (t-test; t-ratio = -14.8; P < 0.0001). Note that these estimates are the same on the link and response scales as the model uses an identity link.
The coefficient (slope) for the effect of a change of latitude on the growth rate is 0.70 ± 0.18 kg year-1 ˚N-1 for females and 1.29 ± 0.18 kg year-1 ˚N-1 for males. There is evidence that these effects (slopes) are different from one another (t-test, t-ratio = -2.3, P = 0.035). These coefficients show that growth rates increase with latitude for both sexes, but that the effect of latitude on growth is higher for male vs. female moose. Note that these estimates are the same on the link and response scales as the model uses an identity link.
This interaction between the effects of latitude and sex on growth is also illustrated in our modelled response predictions: Growth rate of males at 61˚N is 23.0 kg year-1 (95% confidence interval: 21.8 - 24.1 kg year-1) and increases to 25.6 kg year-1 (95% confidence interval: 24.3 - 26.8 kg year-1) at 63˚N. Growth rate of females at 61˚N is 11.4 kg year-1 (95% confidence interval: 10.2 - 12.5 kg year-1) and increases to 12.8 kg year-1 (95% confidence interval: 11.5 - 14.0 kg year-1) at 63˚N.
Figure 4 shows the modelled effects of latitude and sex on growth rate along with my observations.
An increase in annual growth rate with latitude may indicate… [link to mechanisms].
A sex-specific increase in annual growth rate may indicate… [link to mechanisms].
[a discussion on study limitations (e.g. how the growth rate, latitude, etc. were measured)].
The remaining unexplained deviance may be due to other factors affecting growth rate such as winter harshness, food availability, etc. Note that I was not able to include minimum winter temperature in my hypothesis test due to high colinearity between latitude and minimum winter temperature. Therefore, I do not know if the measured latitudinal effect on growth might mechanistically be due to winter harshness (here estimated as minimum winter temperature). This could be tested if I was able to expand my data set to include sites where latitude and minimum winter temperature were less correlated… [discussion on other, untested factors that may be responsible for the unexplained deviance].